MySQL 아키텍처
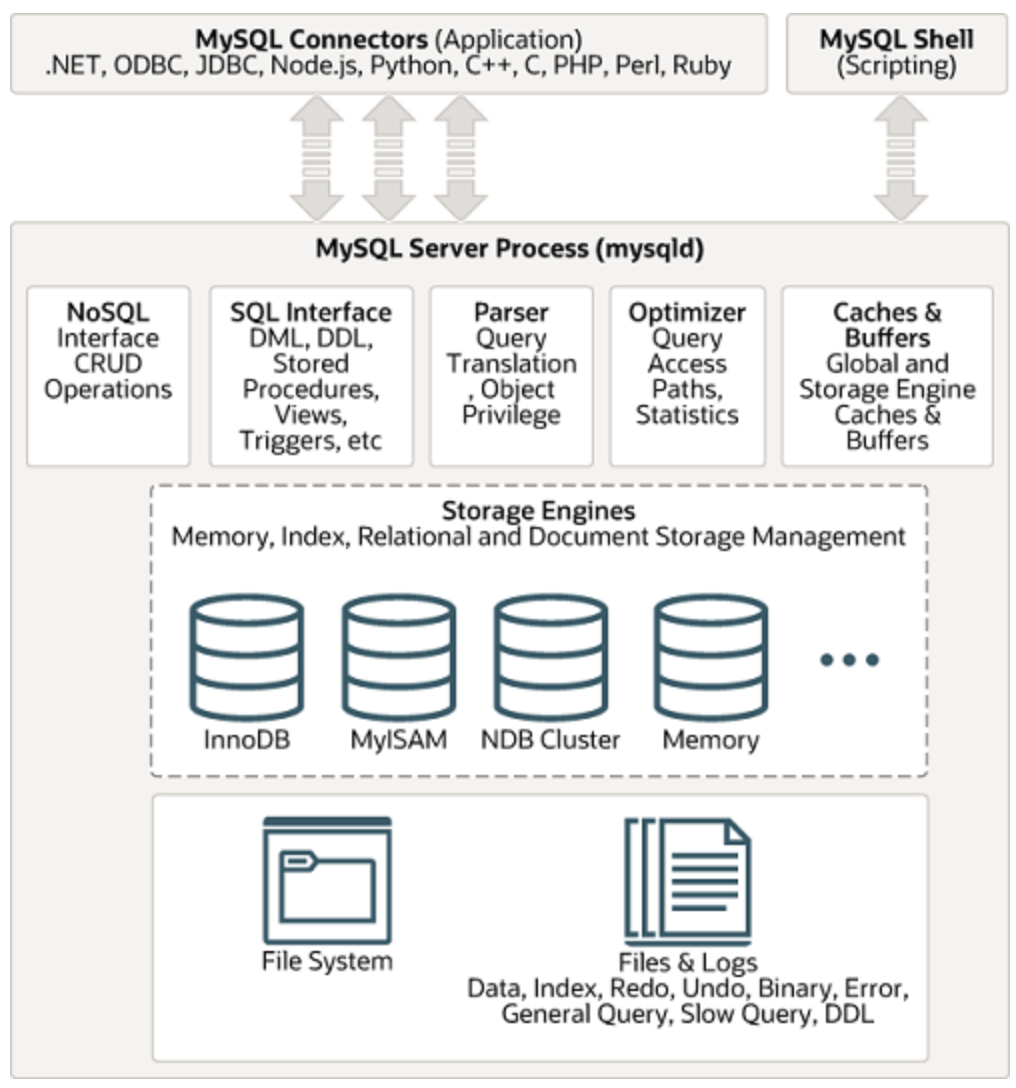
구성
- MySQL 접속 클라이언트
- 역할
- 대부분의 프로그래밍 언어에 대한 접속 클라이언트 제공
- Shell을 통해서도 접속 가능함
- 역할
- MySQL Engine (MySQL의 두뇌)
- 구성
- 옵티마이저
- 요청된 SQL 문을 최적화해서 실행시키기 위해, 실행 계획을 짜는 역할을 함.
- 쿼리 파서
- 전처리기
- 실행 엔진
- 옵티마이저
- 역할
- 클라이언트 접속과 SQL 요청을 처리함.
- 구성
- MySQL 스토리지 엔진 (MySQL의 손발)
- 역할
- 데이터를 실제로 디스크에 저장하거나 디스크에 저장된 데이터를 불러오는 역할
- 옵티마이저가 작성한 실행 계획에 따라서 스토리지 엔진을 적절히 호출해서 쿼리를 실행
- MySQL 엔진이 스토리지를 호출할 때, 사용하는 API를 핸들러 API라고 함
- 직접 구현하여 추가 가능
- 역할
- 운영체제 파일시스템, 하드웨어
쿼리 실행 과정

- 쿼리 캐시에서 실행하고자 하는 쿼리 결과가 존재하는지 확인한다. 있으면 바로 반환하고 없으면 쿼리 파서에 전달한다.
- 쿼리 파서에서 쿼리 문장을 토큰으로 분리해 트리 형태의 구조로 변환한다.
- 전처리기에서 Parse tree를 기반으로 SQL의 문장 구조를 체크합니다.
- 옵티마이저에서 SQL 실행을 최적화해서 실행 계획을 수립합니다.
- 실행 엔진에서 옵티마이저가 만든 실행 계획에 따라, 스토리지 엔진을 호출합니다.
- 스토리지 엔진에서 MySQL 실행 엔진의 요청에 따라 데이터를 디스크로 저장하고 디스크로부터 읽어오는 역할을 담당합니다.
쿼리 캐시
- 역할
- SQL 실행 결과를 메모리에 캐싱하는 역할
- 동일 SQL 실행 시 이전 결과 즉시 반환
- 테이블의 데이터가 변경되면 캐싱된 데이터 삭제 필요 (쿼리 캐시에 접근하는 쓰레드에 Lock이 걸리며, 동시 처리 성능 저하 유발)
- 특징
- MySQL 8.0 부터 완전히 제거됨
쿼리 파서
- 역할
- SQL 문장을 토큰으로 쪼개서 트리로 만듦
- 이 과정에서 쿼리 문장의 기본 문법 오류를 체크함
전처리기 (Preprocessor)
- 역할
- Parse tree를 기반으로 SQL의 문장 구조를 체크함.
- Parse tree의 토큰이 유효한지 체크함.
- Parse tree를 기반으로 SQL의 문장 구조를 체크함.
옵티마이저 (Query Optimizer)
- 역할
- SQL 실행을 최적화해서 실행 계획을 수립함
- 두 가지 방법으로 최적화함
- 규칙 기반 최적화
- 옵티마이저에 내장된 우선순위에 따라 실행 계획 수립
- 비용 기반 최적화
- 작업의 비용과 대상 테이블의 통계 정보를 활용해서 실행 계획 수립
- MySQL을 포함한 대부분의 DBMS에서 이 비용 기반 최적화 방식을 사용함
- 규칙 기반 최적화
쿼리 실행 엔진 (Query Execution Engine)
- 역할
- 옵티마이저가 만든 실행 계획대로 스토리지 엔진을 호출해서 레코드를 읽고 씀.
스토리지 엔진
- 역할
- 쿼리 실행 엔진이 요청하는대로 데이터를 디스크로 저장하고 읽음
- 특징
- 핸들러 API에 의해 동작함
- 핸들러라고도 불림
- 플러그인 형태(인증 등)로 제공됨
InnoDB 스토리지 엔진 아키텍처

- 특징
- 프라이머리 키에 의한 클러스터링
- 트랜잭션 지원 (MVCC, 리두 로그 & 언두 로그, 레코드 단위 잠금)
- 데이터 캐싱 (InnoDB 버퍼풀 사용)
- 어댑티브 해시 인덱스
- 외래키 설정 지원 O
- 클러스터링 테이블 O
- 레코드 단위 잠금 (인덱스 레코드에 대한 잠금)
PK에 의한 클러스터링
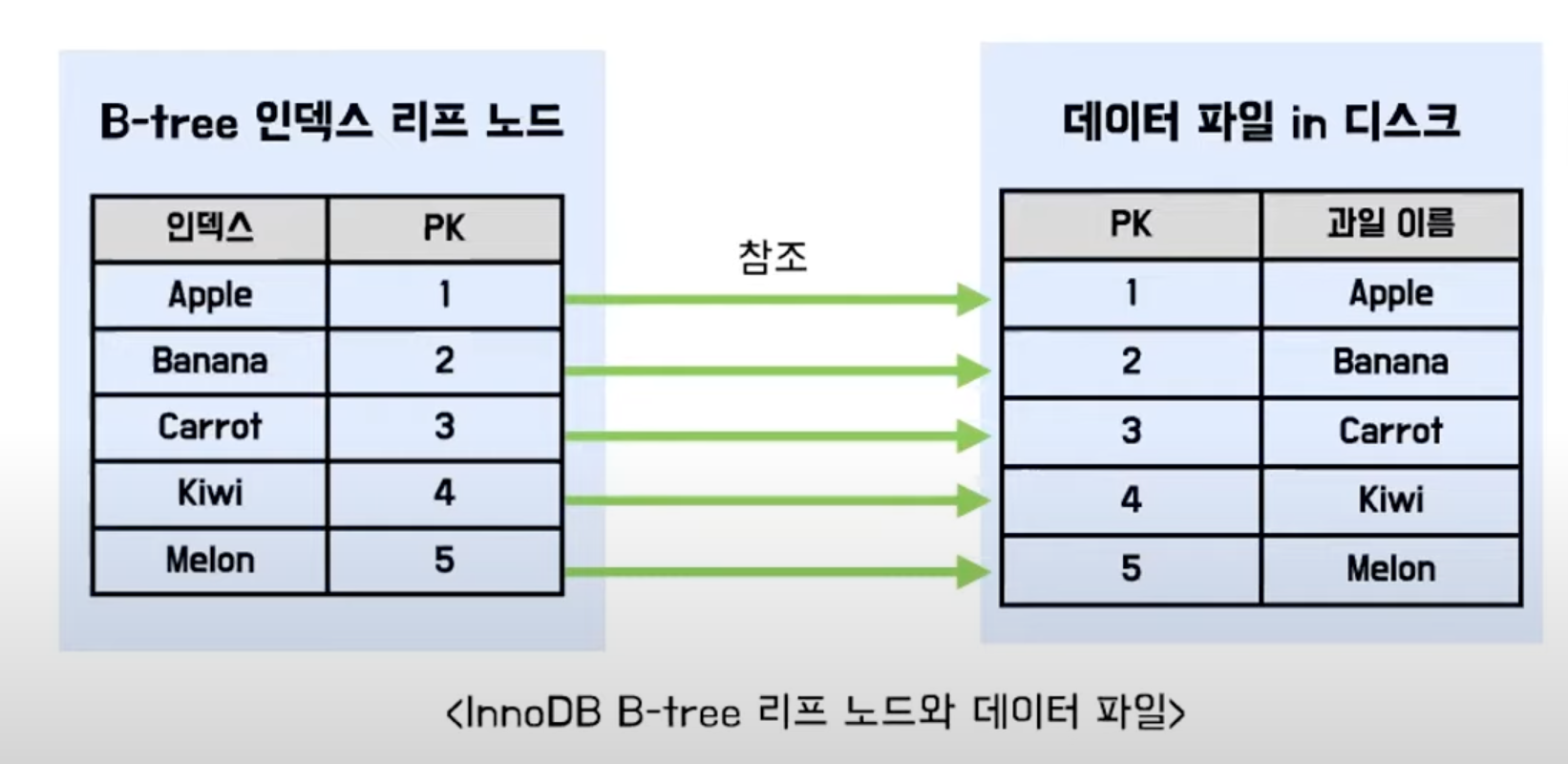
- 특징
- 레코드를 PK순으로 정렬해서 저장.
- PK 인덱스 자동 생성.
- PK를 통해서만 레코드에 접근 가능.
- PK를 통한 범위 검색이 매우 빠름.
- PK 기준으로 데이터가 정렬되어 묶여서 한 군데 저장되어 있기 때문.
- But 클러스터링 때문에 쓰기 성능 저하
- PK 값이 바뀌면 그에 따라 레코드의 물리적 순서도 하나씩 바꿔줘야 하기 때문.
- 웹 서비스의 경우, 쓰기 성능을 희생하고 읽기 성능을 얻는 클러스터링을 하는 것이 합리적임.
- 참고로 InnoDB에서 PK를 지정하지 않으면, 내부적으로 PK를 자동 생성해서 클러스터링한다. 이렇게 내부적으로 생성된 PK는 사용자가 직접 사용할 수 없다. 따라서 InnoDB에서 테이블을 설계할 때는 PK를 직접 설정하는 것이 좋다.
트랜잭션
MVCC(Multi Version Concurrency Control)
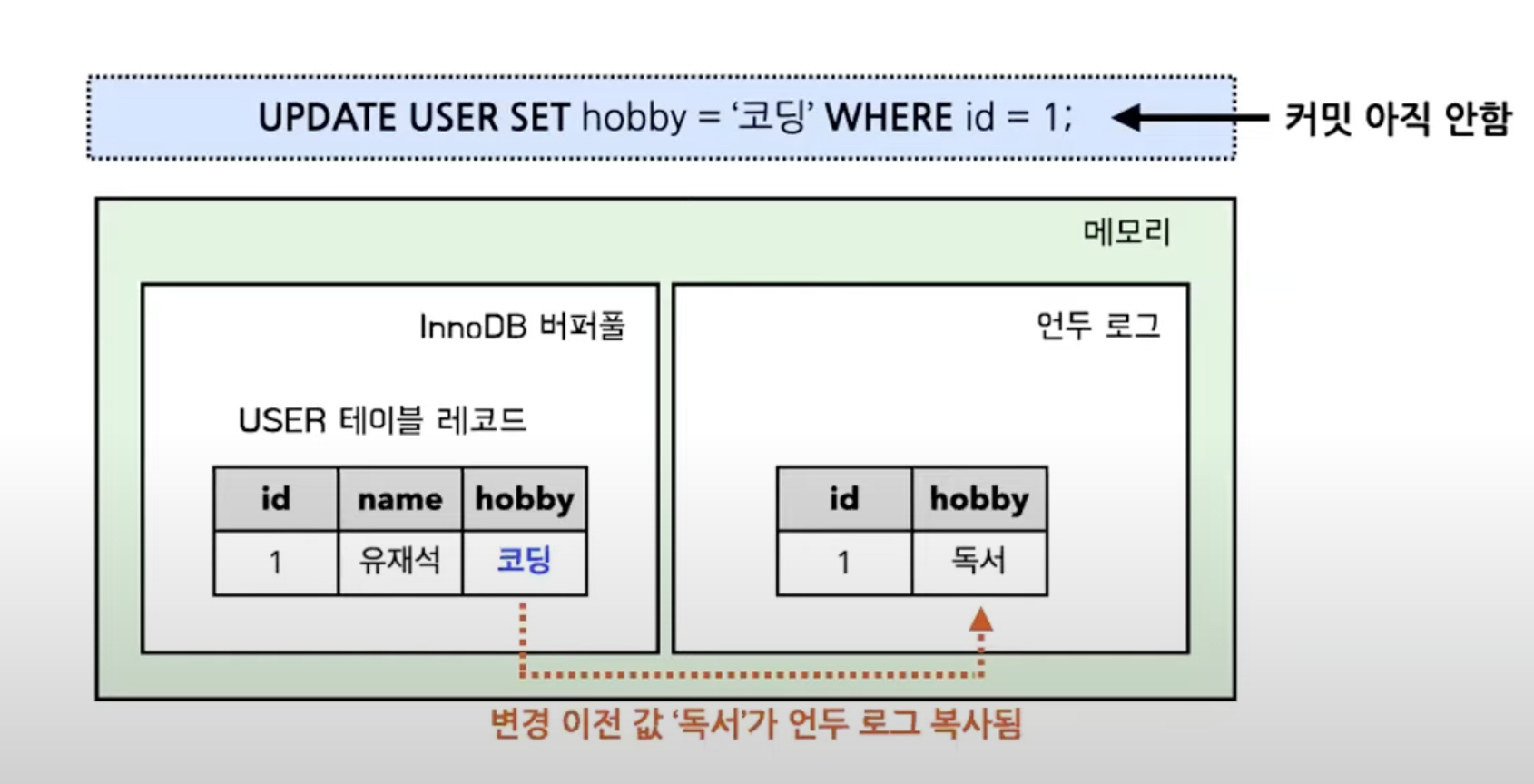
- 위 다이어그램은 데이터베이스의 상태를 나타냄
- InnoDB 버퍼풀은 변경된 데이터를 디스크에 반영하기 전(즉, commit 전)까지 버퍼링하는 공간
- 언두 로그는 변경 시점에 변경되기 이전 데이터를 백업 해두는 공간

- MVCC(Multi Version Concurrency Control)
- 트랜잭션 격리 수준에 따라, 조회 결과가 달라지게 하는 기술
- 이 때 결괏값은 어떻게 될까?
- 트랜잭션 격리 수준이 READ_UNCOMMITED라면 InnoDB 버퍼풀에 저장된 “코딩”을 조회한다.
- READ_COMMITED, REPETABLE_READ, SERIALAZABLE 이라면 언두 로그에 저장된 “독서”를 조회한다.
언두 로그와 리두로그

- 언두로그
- 변경되기 이전 데이터를 백업
- 트랜잭션 보장
- 트랜잭션 격리 수준 보장
- 리두로그
- 변경된 데이터를 백업 (Commit 완료된 데이터)
- 영속성 보장 (서버 비정상 종료시, 리두 로그에 백업된 데이터 복원)
레코드 단위 잠금

- 특징
- 레코드 단위로 잠금을 걸면 동시 처리 성능을 향상시킬 수 있다
- 레코드 자체를 잠그는 것이 아니라, 사실 인덱스 기준으로 잠그는 것
- 예시
- User 테이블의 총 레코드 개수는 5000개
- 성씨 칼럼이 '박'인 레코드는 300개 존재
- 성씨 칼럼이 '박'이고 이름 칼럼이 '병욱'인 레코드는 1개 존재
- 성씨 칼럼에는 idx_성씨 인덱스가 걸려있음
- 예시 설명
- 업데이트 상황에서 먼저 박병욱 레코드를 검색한다.
- 성씨 인덱스 칼럼을 사용한다.
- innoDB는 레코드 자체를 잠그지 않고 인덱스 레코드를 잠그는 방식으로 동작하여, 업데이트 레코드 검색에 사용된 인덱스 레코드를 잠근다.
버퍼풀
- 용도
- 데이터 캐싱
- 인덱스 정보와 데이터 파일을 메모리에 캐싱
- 페이지 단위로 테이블 데이터를 관리
- 페이지 교체 알고리즘으로 LRU 사용
- 쓰기 지연 버퍼
- 변경된 데이터를 버퍼풀에 모았다가, 한 번에 디스크에 기록함
- JPA 영속 컨텍스트의 쓰기 지연 SQL 저장소와 비슷함
- 데이터 캐싱
- 어댑티브 해시 인덱스
- 페이지에 빠르게 접근하기 위한 해시 자료구조 기반 인덱스
- <인덱스 키, 페이지 주소 값> 쌍으로 구성됨
- 자주 요청되는 페이지에 대해 InnoDB가 자동으로 생성하는 인덱스
MyISAM 스토리지 엔진 아키텍처

- 특징
- 클러스터링 지원 X
- 트랜잭션 지원 X
- 외래키 지원 X
- 테이블 단위 잠금
- 키 캐시 사용(인덱스 정보만 버퍼링)
- 전문 검색, 공간 좌표 검색 기능 지원
레퍼런스
반응형
'DB > MySQL' 카테고리의 다른 글
| [Index] 플랫폼 내 페이지네이션 방식에 대한 개선사항 제안 (0) | 2025.01.18 |
|---|---|
| [MySQL] 쿼리 튜닝을 위한 인덱스 활용의 모든 것 (0) | 2024.07.04 |
| [MySQL] Online DDL 활용 방법 (0) | 2024.05.06 |
| [MySQL] MVCC(Multi Version Concurrency Control)란 (0) | 2023.10.28 |
| [DB] 트랜잭션이란 무엇인가? (0) | 2022.06.23 |

댓글