한국기준 2025년 4월 17일 새벽 2시, OpenAI가 최신 AI 모델인 GPT O3와 O4 Mini를 공개했습니다.
이번 발표가 AI 기술의 새로운 시대를 여는 중요한 순간으로 평가받고 있어,
공식 발표된 내용을 기반으로 두 모델의 핵심 기능과 실제 성능에 대해서 빠르게 분석해봤습니다.
잠깐, GPT o? 그게 뭔데?
OpenAI의 GPT o 시리즈는 일반 사용자에게 제공되는 기존 모델인 GPT-4o 와는 다르게,
논리적 추론 능력과 도구 사용 능력을 통해, 복잡한 문제 해결을 위해 설계된 AI 모델 시리즈입니다.
공식 발표는 존재하지 않지만, GLT o 시리즈의 o는 Optimized Reasoning를 의미합니다.
GPT-4o 와의 차이점
GPT-4o의 "o"는 Omni(옴니, "모든 것")로 텍스트, 오디오, 이미지, 비디오 등 모든 형태의 입력·출력 처리 가능한 모델이며,
멀티모달 통합·실시간 상호작용이 주요한 특징을 갖는 모델입니다.
GPT o1 모델
o1 모델은 체계적인 Chain of Thought(생각 흐름) 방식을 통해, 주어진 문제에 대해 다각도로 접근하고 다양한 전략을 시도합니다.
우리가 바로 대답하지 않고 여러 자료들을 참고하고 숙고하여 대답했을 때, 더 질 높은 정보를 제공해줄 수 있는 것과 같은 원리입니다.
주로 아래와 같은 작업에 적합했습니다.
- 복잡한 수학·과학·코딩 문제 해결, 다단계 추론
- 전문가 수준의 논리적 분석, 데이터 과학, 알고리즘 설계
- 시행착오를 통한 학습 및 개선
현재는 o3 모델이 최신 모델로 등록되어 사용 할 수 없지만, 2024년 12월에 정식 출시(2024년 9월 출시)되어 사용할 수 있었습니다.
o2 모델은 정식 출시 기록은 존재하지 않으며, o1 출시 후 o3 모델(2024년 12월 출시, 상용 출시 X) 로 바로 넘어갔습니다.
Why: GPT o3와 o4 Mini를 왜 사용해야 하는가?
현재 GPT o3와 o4 모델은 바로 어제, 2025년 4월 17일 상용 출시 됐습니다. 기존의 GPT o 시리즈 모델들도 뛰어난 성능을 보였지만, 이번에 공개된 GPT O3와 O4 Mini는 특히 현실적인 문제 해결 능력이 탁월하다고 합니다. 모델 자체가 도구(tool)를 능숙하게 사용할 수 있도록 훈련되어 복잡한 작업을 스스로 처리할 수 있으며, 단순한 언어 생성 능력을 넘어 실무에서의 효율성을 극대화할 수 있습니다.
What: GPT O3와 O4 Mini의 혁신적 기능
1. 도구 활용 능력
- GPT O3가 복잡한 문제 해결을 위해 도구를 활용하는 능력
- 실제 사례: 600회 이상 연속 도구 호출 사례
GPT O3 모델은 무려 600회 이상의 연속적인 도구 호출을 통해 복잡한 문제를 스스로 해결할 수 있는 능력을 갖추고 있습니다.
이는 단순 언어 모델을 넘어 실제적인 작업을 수행할 수 있는 AI 시스템으로서의 가능성을 보여줍니다.
2. 멀티모달(Multimodal) 기능
- 이미지와 텍스트 동시 이해 및 처리 능력
- 이미지 기반 작업 능력 소개
O4 Mini는 이미지와 텍스트를 동시에 이해하고 처리할 수 있는 멀티모달 기능을 제공합니다.
예를 들어 복잡하거나 흐릿한 이미지를 분석하고 필요한 정보를 추출하거나, 이미지를 직접 변형하는 작업을 효과적으로 수행할 수 있습니다.
3. 실제 코드 기반 작업 능력
- 코드베이스 내 탐색 및 버그 수정 능력
- 개발자 업무 효율성 향상 가능성 제시
새로운 모델들은 실제 소프트웨어 코드베이스를 탐색하고, 버그를 찾고 수정하는 작업까지 수행할 수 있습니다. 개발자들이 코드 작성 및 유지 보수 과정에서 이 모델을 활용하면 업무 효율성을 획기적으로 개선할 수 있습니다.
GPT o3, o4 모델? 어떤 점이 더 개선됐을까? (실제 사례 및 벤치마크를 통한 성능 검증)
12월에 발표된 자료에 따르면, 아래와 같은 기능적 개선사항이 있었습니다.
- ARC AGI 사상 최고 점수 달성
인간 수준의 일반 지능을 평가하는 ARC AGI 벤치마크에서 03은 87.5%로 인간 평균인 85%를 넘는 최초의 AI로 등극했습니다. 이는 일반화 능력을 요하는 다양한 문제에 대응할 수 있는 잠재력을 보여줍니다.
- 전례 없는 벤치마크 성능
o3는 실생활 코딩 문제 벤치마크인 SweBench에서 71.7% 정확도로 01보다 20% 이상 향상된 성과를 보였습니다. 또한, Codeforces에서는 2727 ELO, 수학 평가인 AIME Benchmark(American Invitational Mathematics Examination)에서는 96.7% 정확도를 달성했습니다.
- 최고 난이도 시험도 돌파
박사급 과학 문제 데이터셋인 GPQA Diamond에서 87.7%의 정확도를 보였고, 가장 어려운 수학 벤치마크인 Epic AI Frontier Math에서도 25% 이상의 정확도를 달성했습니다. 이는 대부분의 다른 모델이 2% 미만을 기록한 것에 비해 압도적인 수치입니다.
- 향상된 안전성 — 심사숙고 정렬 기술 도입
새로운 'deliberative alignment' 기술을 통해 AI가 프롬프트를 스스로 논리적으로 분석하고, 그에 대한 위험 여부를 더 정밀하게 판단할 수 있습니다. 이는 안전성과 정렬성 향상에 핵심적인 진보입니다.

실제로 저 같은 경우에는 개발자로서 코딩을 할 때, GPT-4o 모델 대신 Claude 3.7 Sonnet 모델을 사용하는 경우가 많았는데요,
그 이유는 코딩에 대한 정확도가 높지 않은 경험들을 자주 했기 때문입니다. 그렇지만, 이번 개선을 통해, 코딩 작업도 믿고 맡겨볼 수 있을 것 같습니다.
How: 실제 사용 사례
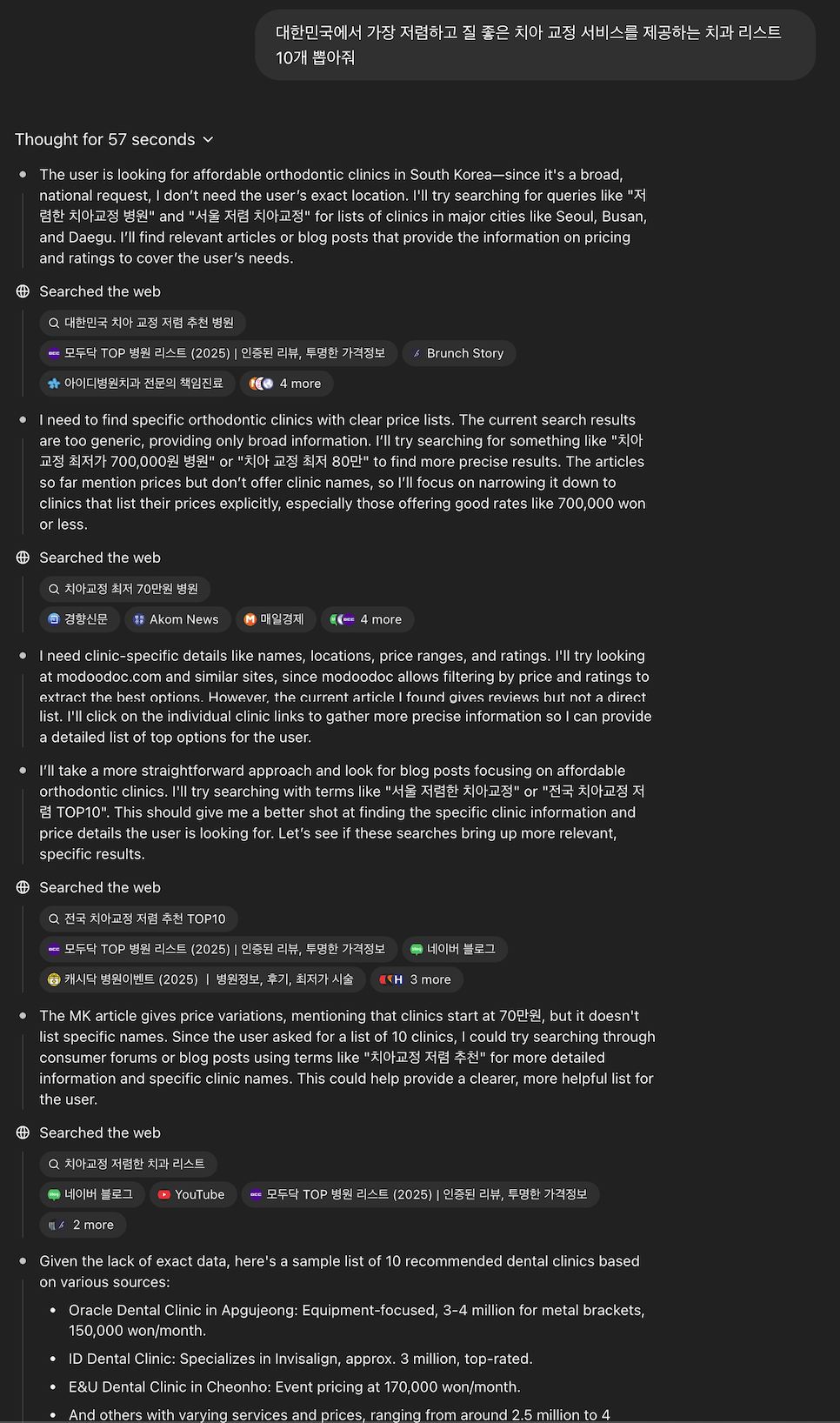
저는 실제로 이번 출시된 o4-mini-high를 활용해, 현재 제게 필요한 자료조사를 맡겼습니다.
바로 응답하지 않고 1분 간, 자료를 조사하고 대답해주는 것을 알 수 있었는데요,
꽤 정확한 답변을 주는 것을 볼 수 있었습니다.

또 GPT 딥 리서치(Deep Reaserch)와 함께 사용하니, 20분 간 자료를 취합하고 정리해서 주는 것을 알 수 있었습니다.
결론
최신 GPT o3, o4 Mini 모델은 단순한 언어 모델을 넘어, 도구를 능숙하게 활용하며 현실의 복잡한 문제들을 실제적이고 효율적으로 해결할 수 있는 진정한 AI 시스템으로 진화했습니다.
o3, o4 모델의 공개로 과학적 연구부터 일상 업무까지 다양한 분야에서 큰 변화가 예상됩니다.
이제 여러분이 이 강력한 AI 모델로 무엇을 창조할 수 있을지 기대됩니다.
레퍼런스
https://hyunicecream.tistory.com/116
https://www.magicaiprompts.com/blog/openai-o1-introduction-and-comparison-with-gpt4o
https://www.youtube.com/watch?v=sq8GBPUb3rk&ab_channel=OpenAI
'LLM > GPT' 카테고리의 다른 글
| GPT란 정확히 뭘까? 개발자도 자주 헷갈리는 AI 모델 개념 이해하기 (0) | 2025.04.16 |
|---|

댓글